인공지능(AI)의 기술은 이제 전 산업 분야에서 활용될 정도로 빠르게 확산되고 있는 추세이며, 이에 따른 인공지능 개발자에 대한 수요도 높아지고 있습니다.
그리고, 이런 관심과 수요를 반영하여 인공지능 개발의 현주소를 짚어보고 현장의 목소리를 들을 수 있도록, 현장 연구개발 책임자들이 전하는 오직 개발자만을 위한, AI 전문가가 되고 싶은 분을 위한 온/오프라인 밋업이 개최되었습니다.
이번 행사는 인공지능 전문기업 솔트룩스와 솔트룩스벤처스가 주최하였으며, 지난 10월 25일 서울 역삼 포스코 타워 3층 이벤트 홀에서 개최되었습니다.
AI기술 밋업 세미나 "초거대 언어모델의 SOTA와 미래전망", "생성적 AI와 멀티모달 인지", "혁신 서비스를 위한 AI 기술사례" 등 3개 세션 총 14개 강연으로 구성되었으며, 인공지능 분야로 취업을 꿈꾸는 예비 및 현업 개발자들이 업계의 최신 동향과 연구 성과, 실무 노하우 등 업계의 생생한 목소리를 들을 수 있는 자리로 마련되었습니다.

그중에서 김재은 랩장을 통해 소개된 지식 기반 대화 서비스를 위한 초거대 언어모델 상용화 방안에서는, 최신 언어 모델 트렌드를 통해 느끼는 인사이트를 공유하고 솔트룩스에는 이러한 언어모델 기술을 어떻게 상용화하려고 하고 있는지 들을 수 있는 시간이었습니다.

그래프를 통해 랭귀지 모델의 급격한 변화에 대한 내용을 소개하고 있는데, 2년 사이에 랭귀지 모델 자체가 상당히 커지고 있다는 것을 설명해 주고 있습니다.
트랜스포머 모델을 제외한 모든 AI 모델들이 2년 사이에 8배 정도 커졌다고 했을 때, 트랜스포머 모델의 경우 약 275배 정도로 커졌을 정도로 급격하게 변화되고 있음을 알 수 있습니다.


요즘 많이 이야기하고 있는 초거대, 대규모, 하이퍼 랭귀지 모델의 정의에 대해서도 들을 수 있었습니다.
GPT-3 논문의 일부에서도 175 빌리언의 파라미터로 학습된 랭귀지 모델이거나 아주 큰 랭귀지 모델이다 정도로 요약하였는데, 명확한 정의가 내려진 것은 없기 때문에 크기를 키운 랭귀지 모델이라는 정도로 이해할 수 있었습니다.


그리고 이런 랭귀지 모델을 계속 키우고 있는 이유와 한계에 대해서도 이야기하고 있습니다.
GPt-3, 구글 람다 논문을 통해 이야기하는 것은 모델 크기가 커질수록 대화 역량이 향상된다는 것입니다. 하지만, 크기에만 집중한 언어 모델의 한계에 대한 이야기도 빠지지 않았습니다.
자연어 이해에 기반한 추론(Reasoning) 문제에서는 모델 사이즈를 키운다고 해서 되는 게 아니며, 대화를 하는 부분에 대해서도 AI가 하는 말이 안전(Safety) 한지, 사실성(Groundedness)에 기반한 것인지에 서는 사람보다 한참 못 미치는 품질을 보여주고 있다고 합니다.

데이터만 많이 넣고 파라미터만 크게 늘려 놓아 학습을 시켰을 때 신기하긴 하지만 상용화할 수 있는 수준은 아니라는 결론을 내렸고, 단순한 프롬프트가 아닌 명확한 가이드와 지침을 통한 휴먼 피드백으로 학습을 시켰더니 더 똑똑해지고 훨씬 큰 성능 향상을 보여 준 것을 알 수 있었다고 합니다.

또한, 진짜인지 아닌지 사실성을 어떻게 판단하고 어떻게 신뢰할 수 있으며 위협이 되는 요소는 없는지 판단하기 위해, 만들어진 사실이 있는 지식들을 검색을 통해 가져와 참고하는 형태로 만들었더니 훨씬 더 안전하고 사실성에 기반한 대화를 만들 수 있다는 것을 알 수 있었다고 합니다.

중반 이전까지는 최근에 느낌 인사이트와 트렌드를 공유하는 시간을 가졌다면, 이후부터는 솔트룩스에서는 어떻게 이 언어모델들을 상용화하려고 하고 있으며 연구개발하고 있는지 한 장의 사진으로 표현하고 설명하는 시간도 가졌습니다.
그렇게 탄생한 LUXIABOT은 앞에서 이야기한 최신 트렌드 중에서 언어 모델을 잘 활용하기 위한 요소요소들을 가져와서 LUXIABOT에 적용한 결과라고 합니다.
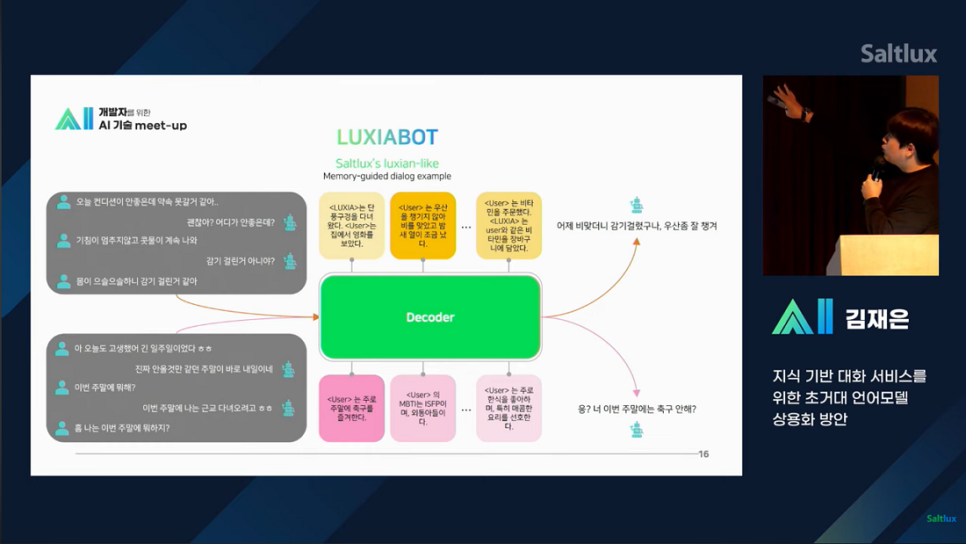
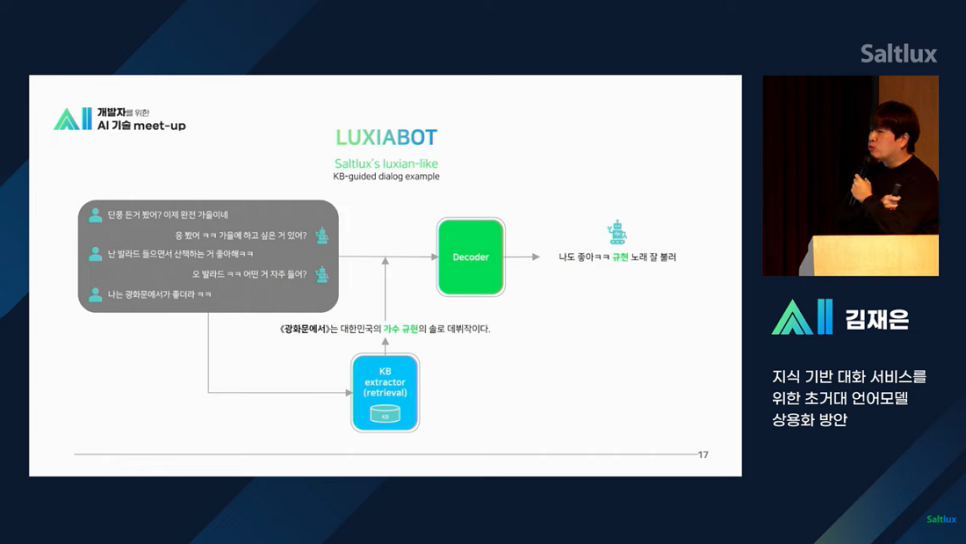
좀 더 구체적인 예시를 통해 어떻게 메모리를 생성하는지에 대해서도 확인해 볼 수 있었습니다.
연구개발 모델인 MRC Sum과 KB extractor을 통해 유저와 대화한 주요 내용은 어떻게 요약되며 메모리화하는지 과정을 예시를 통해 확인해 볼 수 있었고, 실제 어떤 방식으로 유저에 최적화된 대화를 할 수 있도록 만들었는지 알아보는 시간도 있었습니다.

메타 휴먼 상용화를 목표로 하고 있는 솔트룩스는 LUXIABOT 한지아에게 디테일한 persona를 지속적으로 만들어 반영하고 있으며, 올 연말을 시점으로 메타 휴먼 한지아부터 LUXIABOT을 적용하는 것을 준비하고 있다고 합니다.

마지막으로 솔트룩스는 선행연구조사 SOTA 모델 프로토타이핑, 상용제품 서비스 문제를 이해, 분석, 해결 방안 제시 및 솔루션 연구 개발에 대한 업무를 진행하고 있으며, 그 외에도 자연어 처리, 음성 인식, 음성 합성 등 다양한 AI 연구 분야에 대해 관심 있는 신입/경력/전문연구요원을 모집하는 내용을 공유하기도 하였습니다.
해당 부분은 대략 30분 정도 되는 시간이라 부담 없을 것 같은데요, AI 분야에 관심 있는 개발자라면 시청해 보시기 바랍니다.
랭기지 스튜디오
다양한 인공지능 서비스에 꼭 필요한 맞춤형 언어모델 구축 플랫폼, 초거대언어모델, 대용량언...
www.saltlux.com

[본 게시글은 솔트룩스로부터 소정의 원고료를 제공받아 작성되었습니다.]




댓글